Now it’s time for my favourite graph visualization framework. As an introduction I cite from the Cytoscape website:
Cytoscape is an open source software platform for visualizing molecular interaction networks and biological pathways and integrating these networks with annotations, gene expression profiles and other state data.
Cytoscape.js as a side project is a JavaScript library designed to build graph theory related data evaluation and visualization applications on the web. It comes with some layout renderers but is open to other visualization libraries such as Cola.js. Cola is a constraint based layout library with some very interesting features. In this context, we will use it only as a layout engine for the graph.
How does it look?
When playing around with this graph you will probably notice two things:
- When dragging around a single node all the other nodes of the graph remain calm and don’t wiggle around like in most physical based layouts.
- When reloading this page you will always see the same arrangement of nodes. The graph is stable to reloads.
These two feature result from the way Cola.js renders the graph and are very useful for real world applications. While it’s big fun wobbling and dragging around nodes in a real application you would always like to see the same graph when reloading the same data. And manipulating the arrangement should not affect nodes not touched. The complete source code can be found in the ![]() GitHub repository.
GitHub repository.
How does it work?
Once again we start by including the stuff needed. And this are the two libraries and an adaptor to use Cola.js from within Cytoscape.js:
<script src="/graphs/common/cola.js"></script> <script src="/graphs/common/cytoscape.js"></script> <script src="/graphs/common/cytoscape-cola.js"></script>
The adaptor can also be found on GitHub.
The HTML body contains a div to render the graph into:
<div id="cy"></div>
The remainder of the index.html file consists of a script:
var elems = [
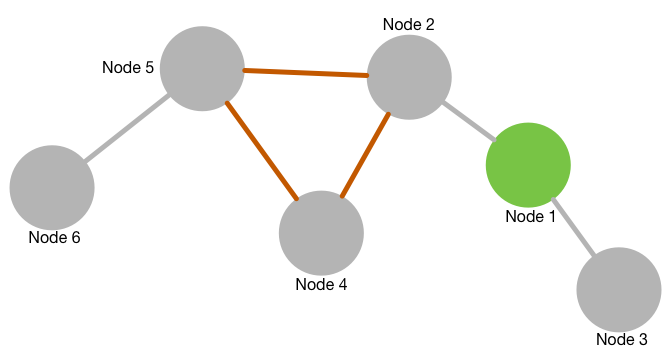
{data: {id: '1', name: 'Node 1', nodecolor: '#88cc88'}},
{data: {id: '2', name: 'Node 2', nodecolor: '#888888'}},
{data: {id: '3', name: 'Node 3', nodecolor: '#888888'}},
{data: {id: '4', name: 'Node 4', nodecolor: '#888888'}},
{data: {id: '5', name: 'Node 5', nodecolor: '#888888'}},
{data: {id: '6', name: 'Node 6', nodecolor: '#888888'}},
{
data: {
id: '12',
source: '1',
target: '2',
linkcolor: '#888888'
},
},
{
data: {
id: '13',
source: '1',
target: '3',
linkcolor: '#888888'
},
},
{
data: {
id: '24',
source: '2',
target: '4',
linkcolor: '#ff8888'
},
},
{
data: {
id: '25',
source: '2',
target: '5',
linkcolor: '#ff8888'
},
},
{
data: {
id: '45',
source: '4',
target: '5',
linkcolor: '#ff8888'
}
},
{
data: {
id: '46',
source: '4',
target: '6',
linkcolor: '#888888'
}
}];
var cy = cytoscape({
container: document.getElementById('cy'),
elements: elems,
style: cytoscape.stylesheet()
.selector('node').style({
'background-color': 'data(nodecolor)',
label: 'data(name)',
width: 25,
height: 25
})
.selector('edge').style({
'line-color': 'data(linkcolor)',
width: 3
})
});
cy.layout({name: 'cola', padding: 10});
Lines 2 to 7 define the nodes with their name/caption and colour. Lines 8 to 54 define the edges in a similar way. Lines 56 to 70 define the Cytoscape container and attach dynamic properties to the nodes and edges. Line 71 finally kicks off the layout rendering. Note: up to that last line we specified exactly no rendering or geometry information! By changing the name of the renderer from cola to one of the built-ins (circle or cose are fun to play with!) you can get a completely different outout.
As a last remark I strongly recommend to have a look at the graph theoretical and practical routines and algorithms the Cytoscape.js library has to offer.
 Some software systems are designed for massive amounts of data to be processed in a very short time. Banking systems, fraud detection, billing systems. Lets pick one, I worked on for a long time: billing systems (for telecom or internet providers for example).
Some software systems are designed for massive amounts of data to be processed in a very short time. Banking systems, fraud detection, billing systems. Lets pick one, I worked on for a long time: billing systems (for telecom or internet providers for example).