Just a little reminder: pip has this very useful option to install a bunch of packages from a single text file mostly called requirements.txt. Anaconda’s command line tool conda doesn’t support this option directly. It does support reading the package names from a file using the –yes and –file option
Just a little reminder: pip has this very useful option to install a bunch of packages from a single text file mostly called requirements.txt. Anaconda’s command line tool conda doesn’t support this option directly. It does support reading the package names from a file using the –yes and –file option
conda install --yes --file requirements.txt
but that does not automatically install all the dependencies. To do this, we need to iterate over the file and install each package in “single package mode”:
while read requirement; do conda install --yes $requirement; done < requirements.txt
Thanks to Luis Capelo for this snippet which I use to install dependencies in a dockerized instance of Anaconda / Jupyter (more on that in a later post).
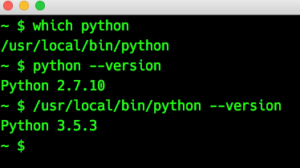 Yes, this is strange, isn’t it? The PATH variable is set in the correct order (this is why ‘which’ finds the local Python). Googling about this behavior at first didn’t bring up any solution. But then I came across
Yes, this is strange, isn’t it? The PATH variable is set in the correct order (this is why ‘which’ finds the local Python). Googling about this behavior at first didn’t bring up any solution. But then I came across