One of the best known visualization frameworks is D3.js. Written by Mike Bostock, the data visualization superstar about whom Edward Tufte said “that he will become one of the most important people for the future of data visualisation” (according to Wikipedia). And who am I to object to Edward Tufte?
So D3 is in its core an SVG handling library around which several so called layouts for different (actually a lot of) types of diagrams gather. One of them is the so called force-directed graph, which is exactly what we will use here.
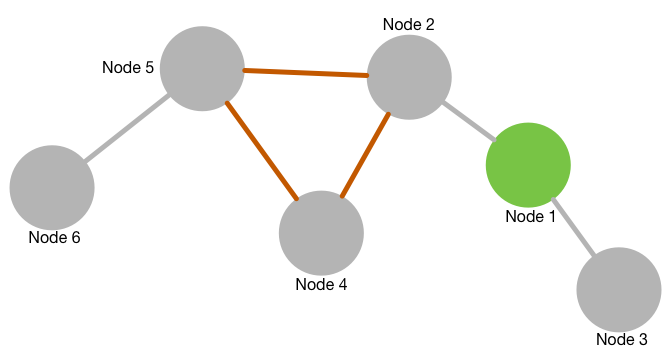
How does it look?
This is a real physical simulation (although featuring some shortcuts for reduced calculation time) which means that the arrangement of the nodes when reloading the page is a new one every time and dragging around one node lets the others wobble around. One of the shortcuts is that the repulsive force only is active between nodes connected. So dangling ends can cross edges with the rest of the graph. Nevertheless playing around with the mesh can be fun for some time. The complete source code can be found in the ![]() GitHub repository
GitHub repository
How does it work?
Once again it all starts with including the libraries:
<script src="/graphs/common/jquery-2.1.3.js"></script> <script src="/graphs/common/d3.js"></script>
The we add some style for nodes and text:
<style>
.node g text {
font: 10px sans-serif;
pointer-events: none;
text-anchor: middle;
}
.node:not(:hover) .nodetext {
display: none;
}
text {
fill: #000;
font: 10px sans-serif;
pointer-events: none;
}
</style>
Next we define some variables:
var width = 800, height = 500; var n = 10000, force, svg, drag;
The first line defines width and height of the SVG element, the second line defines n as the number of iterations to be done (I’ll explain later) and the global variables force, svg and drag.
Next we need to define the nodes and edges or links. For the sake of simplicity I’ll do that once again inline. In a real application you would load the dataset in the background:
var nodes = [
{
"name": "Node 1",
"nodeid": 1,
"nodecolor": "#88cc88",
"x": 0,
"y": 0,
},
...
{
"name": "Node 6",
"nodeid": 6,
"nodecolor": "#888888",
"x": 0,
"y": 0,
}
];
var links = [
{
"source": 0,
"target": 1,
"linkcolor": "#888888"
},
...
{
"source": 3,
"target": 5,
"linkcolor": "#888888"
}
];
Then I wrapped up the whole generation and execution of the graph into a function called performGraph():
function performGraph() {
force = d3.layout.force()
.charge(-1000)
.theta(1)
.linkDistance(170)
.size([width, height])
.on("tick", tick);
drag = force.drag()
.on("dragstart", dragstart)
.on("dragend", dragend);
svg = d3.select("body").append("svg")
.attr("id", "thissvg")
.attr("width", width)
.attr("height", height);
link = svg.selectAll(".link");
node = svg.selectAll(".node");
force.nodes(nodes).links(links);
force.start();
for (var i = n; i > 0; --i) {
force.tick();
}
force.stop();
link = link.data(links)
.enter()
.append("g")
.attr("class", "glink")
.append("line")
.style("stroke-width", "3")
.attr("class", "link")
.attr("x1", function (d) {
return d.source.x;
})
.attr("y1", function (d) {
return d.source.y;
})
.attr("x2", function (d) {
return d.target.x;
})
.attr("y2", function (d) {
return d.target.y;
})
.attr("stroke", function (d) {
return d.linkcolor;
});
node = node.data(nodes)
.enter().append("g")
.attr("class", "node")
.attr("nodeid", function (d) {
return d.nodeid
})
.attr("transform", function (d) {
return "translate(" + d.x + "," + d.y + ")";
});
node.append("circle")
.attr("r", "15")
.attr("fill", function (d) {
return d.nodecolor;
})
//.attr("fill", "#888888")
.attr("fill-opacity", "1")
.attr("cx", "0")
.attr("cy", "0");
node.append("text")
.attr("x", 12)
.attr("dx", "0.5em")
.attr("dy", "0.5em")
.attr("class", "nodecaption")
.attr("display", "inline")
.text(function (d) {
return d.name;
});
node.call(drag);
}
Lines 2 to 7 set up the force layout engine with some physical parameters, the width and height and an event handler for the ticks. Ticks are D3’s simulation steps. For every tick, a function is called and the positions of the elements are recalculated. We’ll discuss the tick function further down.
Then we define a drag event listener in line 8 to 10 binding its events to two functions called dragstart and dragend. More on those later. Lines 11 to 14 show how to manipulatie the DOM using D3 by adding an SVG element with some attributes to the body.
Lines 15 and 16 handle one of the (for me) most counterintuitive features of D3: we select DOM elements by class that aren’t yet there. Line 17 attaches the nodes and links datasets to the force layout. Line 18 kicks off the physical simulation, line 22 stops it. The for-loop in between counting down from 10000 (the n variable, you remember?) executes 10000 times the force.tick() function. We also could have started the simulation and let it run infinitely but this start-stop handling provides for a steady graph instead of one always wiggling around a bit.
Lines 23 to 44 define, what to do with the links by appending a g (for group) SVG element to the SVG canvas and adding line to the group. Lines 45 to 53 do something similar with the nodes adding a group and a transformation function. In lines 54 to 62 we add a AVG circle element using the nodecolor attribute from the nodes dataset. Lines 63 to 71 finally add the text label to the nodes. Line 72 eventually binds the nodes to the drag event object to allow for the dragging of nodes with a mouse.
Now we need to define all the helper functions bound to event listeners in code above. First the tick() function to do the simulation steps:
function tick() {
link.attr("x1", function (d) {
return d.source.x;
})
.attr("y1", function (d) {
return d.source.y;
})
.attr("x2", function (d) {
return d.target.x;
})
.attr("y2", function (d) {
return d.target.y;
});
node.attr("transform", function (d) {
return "translate(" + d.x + "," + d.y + ")";
});
}
And the dragging functions:
function dragstart(d) {
force.stop();
}
function dragend(d) {
force.stop();
}
The last thing to do: kick it to action by calling performGraph():
performGraph();
Why exactly did I put all the code into a function to call it in the end? In a real application you would have some additional GUI elements for example to switch on and of different types of nodes or labels etc. Every time this is done we need to recalculate the graph. Now this can be done with one function call.
 Today I paged through a book by
Today I paged through a book by