If you see strange connection problems when building docker images on MacOS after updating to Big Sur the reason might be a change in some implementations in the network layer. And the Docker Desktop update doesn’t take these into account because fixing the issue means to delete everything previously built on your machine.
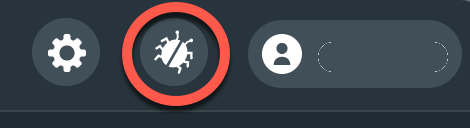
Spcifically, open the Docker Desktop app and klick on the bug icon in the upper right corner:
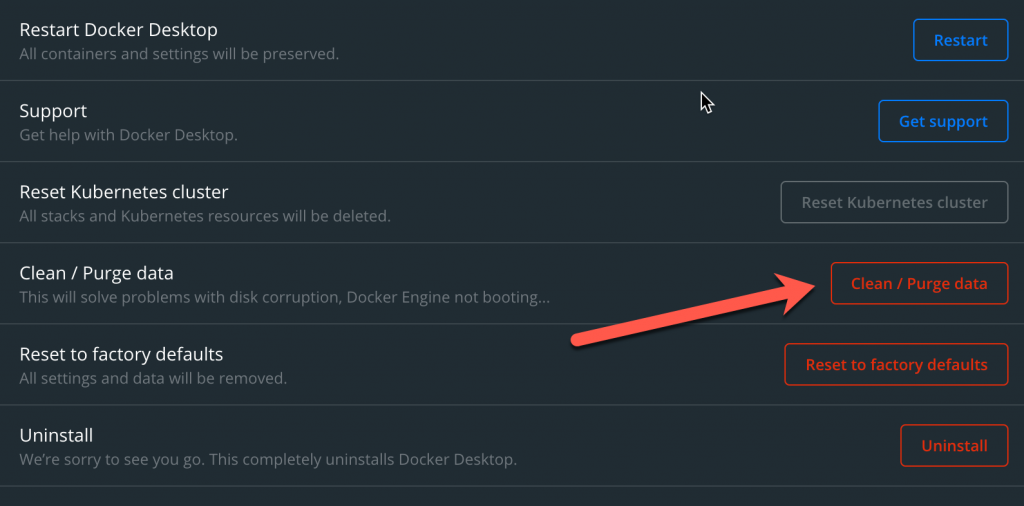
When the dialog opens, click on “Clean / Porge data”
This will take some time since docker will restart after cleaning. But then your network problems should be gone.
Sometimes you have a set of environment variables in a .env file. And sometimes you would like to consume them in a shell script. You can do that like this:
export $(cat .env | xargs)
In some special cases you might have the .env file somewhere on the net and would like to include it. Here curl comes in handy:
This is part one of a short series of posts about Dash. The repository for this blog posts is here.
Dash is an application framework to build dashboards (hence the name) or in general data visualization heavy largely customized web apps in Python. It’s written on top of the Python (web) micro-framework Flask and uses plotly.js and react.js.
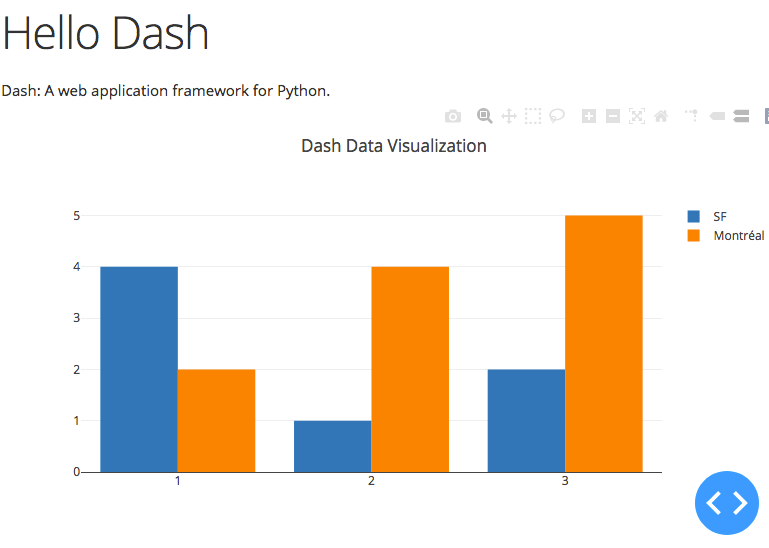
The Dash manual neatly describes how to setup your first application showing a simple bar chart using static data, you could call this the ‘Hello World’ of data visualization. I always like to do my development work (and that of my teams) in a dockerized environment, so it OS agnostic (mostly, haha) and the everyone uses the same reproducible environment. It also facilitates deployment.
So let’s gets started with a docker-compose setup that will probably be all you need to get started. I use here a setup derived from my Django docker environment. If you’re interested in that one too, I can publish a post on that one as well. The environment I show here uses (well, not for the Hello World example, but at some point you might need a database, so I provide one, too) PostgreSQL, but setups with other databases (MySQL/MariaDB for relational data, Neo4J for graph data, InfluxDB for time series data … you get it) are also possible.
We’ll start with a requirements.txt file that will hold all the pyckages that need to be installed to run the app:
psycopg2>=2.7,<3.0 dash==1.11.0
Psycopg is the Python database adapter for PostgreSQL and Dash is … well, Dash. Here you will add additional database adaptors or other dependencies your app might use.
Next is the Dockerfile (and call it Dockerfile.dash) to create the Python container:
FROM python:3
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
COPY requirements.txt /code/
RUN pip install -r requirements.txt
COPY . /code/
We derive our image from the current latest Python 3.x image, the ENV line sets the environment variable PYTHONUNBUFFERED for Python to one. This means, that stdin, stdout and stderr are completely unbuffered, going directly to the container log (we’ll talk about that one later). Then we create a directory named code in the root directory of the image and go there (making it the current work directory) with WORKDIR. Now we COPY the requirements.txt file into the image, and RUN pip to install whatever is in there. Finally we COPY all the code (and everything else) from the current directory into the container.
Now we create a docker-compose.yml file to tie all this stuff together and run the command that starts the web server:
We create two so called services: a database container running PostgreSQL and a Python container running out app. The PostgreSQL container uses the latest prebuilt image, we call it dash_pgsql and we set some variables to initiate the first database and the standard database user. You can later on certainly add additional users and databases from the psql command line. To do this we export the database port 5432 to the host system so you can use any database you already have tool to manage what’s inside that database. Finally we persist the data using a shared volume in the subdirectory pgdata. This makes sure we see all the data again when we restart the container. Then we set up a dash container using our previously created Dockerfile.dash to build the image and we call it dash_dash. This sounds a bit superfluous but this way all containers in this project will be prefixed with “dash_“. If you leave that out docker-compose will use the projects directory name as a prefix and append a “_1” to the end. If you later use Docker swarm you will possibly have multiple containers for the same service running and then they will be numbered. The command that will be run when we start the container is python app.py. We export port 8080 (which we set in the app.py, bear with me) to port 80 on our host. You might have some other process using that port. In this case change the 80 to whatever you like (8080 for example). Finally we declare that this container needs the PostgreSQL service to run before starting. This currently is not needed but will come handy later, since the PostgreSQL containers might be a bit slow in startup. And then your app might start without a valid database resource.
The last building block is our app script itself:
import dash
import dash_core_components as dcc
import dash_html_components as html
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = dash.Dash(name, external_stylesheets=external_stylesheets)
app.layout = html.Div(children=[
html.H1(children='Hello Dash'),
html.Div(children='''
Dash: A web application framework for Python.
'''),
dcc.Graph(
id='example-graph',
figure={
'data': [
{'x': [1, 2, 3], 'y': [4, 1, 2], 'type': 'bar', 'name': 'SF'},
{'x': [1, 2, 3], 'y': [2, 4, 5], 'type': 'bar', 'name': u'Montréal'},
],
'layout': {
'title': 'Dash Data Visualization'
}
}
)
])
if __name__ == '__main__':
app.run_server(host='0.0.0.0', port=8080, debug=True)
I won’t explain too much of that code here, because this just is the first code example from the Dash manual. But note that I changed the parameters of app.run_server(). You can use any parameter here that the Flask server accepts.
To fire this all up, use first docker-compose build to build the Python image. Then use docker-compose up -d to start both services in the background. To see if they run as ppalnned use docker-compose ps. You should see two services:
Name Command State Ports
-----------------------------------------------------------------------------
dash_dash python app.py Up 0.0.0.0:80->8080/tcp
dash_pgsql docker-entrypoint.sh postgres Up 0.0.0.0:5432->5432/tcp
Now point your browser to http://localhost (or appending whatever port you have used in the docker-compose file) and you should see:
You now can use any editor on your machine to modify the sourcecode in the project directory. Changes will be loaded automatically. If you want to look at the log output of the dash container, use docker-compose logs -f dash and you should see the typical stdout of a Flask application, including the debugger pin, something like:
dash_1 | Running on http://0.0.0.0:8080/ dash_1 | Debugger PIN: 561-251-916 dash_1 | * Serving Flask app "app" (lazy loading) dash_1 | * Environment: production dash_1 | WARNING: This is a development server. Do not use it in a production deployment. dash_1 | Use a production WSGI server instead. dash_1 | * Debug mode: on dash_1 | Running on http://0.0.0.0:8080/ dash_1 | Debugger PIN: 231-410-660
Here you will also see when you save a new version of app.py and the web server reloads the app. To stop the environment first use CTRL-c to exit the log tailing and issue a docker-compose down. In an upcoming episode I might show you some more things you cound do with Dash and a database.
The law of the instrument states that if your only tool is a hammer, you are tempted to treat everything as a nail. In modern business this hammer often is Excel. Every time someone needs a little (or larger) tool to do some work, in many companies the result is an Excel spreadsheet with lots of logic, programming and formatting in it. It’s tempting since in a corporate environment nearly everyone has an office suite on their computer. An obvious solution is hacked together pretty fast and often never again understood, but more on that later. There are however some fundamental problems with applications becoming spreadsheets:
They are inherently not multi-user capable.
They are not versioned. Everyone has some version or the other of the file. Nobody knows which is the newest.
They are not maintainable or understandable for someone else as the author or later on even by the author.
Data, code and visualization literally live within the same space.
Why
are those things generally and inherently bad? Aren’t there legitimate
use cases for „Excel apps“? Let’s give all the shortcomings a closer
look.
Not multi-user capable
Without using special server components Office documents are not multi-user capable. The start of all misery often is a mail, spreading a document among several people. Then some or all of them start to make changes. If they don’t synchronize who works in which order on the document (and sending around updated versions of the corpus delicti!) the proliferation of conflicting versions will drive you mad some time later.
No versioning
Different people will have different versions of the document. Even you yourself might have different versions, if you chose not to overwrite the existing file: My_Important_Calculation_2019-01-05.xlsx, My_Important_Calculation_2019-01-07.xlsx, My_Important_Calculation_2019-01-07_better_version.xlsx … sounds familiar, eh? I hope I don’t need to explain why this is bad.
Lack of maintainability
Ever tried do decipher a formula as long as the Panamericana crammed in a cell the size of a fruit fly? And now imagine trying to understand what the whole worksheet does by clicking into each and every cell and try to figure out what happens therein. I know there are people who are able to grasp an overall view of a worksheet they never saw before. But I prefer to use my brains computational power to solve the underlying business case or problem instead of an encrypted version of it in a worksheet.
One-pot solution
Your data (the numbers and texts in cells), your code (formulas) and visualization (some inline created graphics) literally live in the same place, your worksheet. You could try to separate the code by using Visual Basic for applications or some more modern replacement but this solves the problem only partially. And you lose some of the just in time synchronous tooling which is one of the few advantages of the Office solution.
So what?
Writing good readable and maintainable code is empathy with your team and your future self. The hardship you go through when you rely on office “applications” for your business mostly was created by yourself and / or your team. At least for the cases you and your team is responsible, you can do better. Set up an application dedicated to your business problem. There are technical solutions that allow you to do so in a fast and agile way. You can put that solution on a central server so everyone has access. You can back up that server or service to prevent data loss. And your solution will have a much better user experience. And don’t tell me your company is not a software company because you produce goods or sell services. Thinking this way is sort of a déformation professionnelle (french term for “looking at things from the point of view of one’s profession”). If you deploy some code (in whatever environment), at least part of your company indeed is a software company. Don’t take me for that, maybe you put more confidence in General Electric’s CEO Jeff Immelt who said in an interview with Charlie Rose “Every company has to be a software company”.
Nearly everyone working in software development has seen or was confronted with career ladders. These nifty listings of levels for employees. Many people think about the relevance of those ladders for their own career or their teams and companies. Career ladders can be a good way to get some orientation about the inherent questions of our job:
Where am I now in the sense of career or growth path?
Where am I going? What are my opportunities?
However since career ladders is a very central point and also an often tacitly used one, let me point out some things I learned from my own experience as a developer and engineering manager and from other people. I will list some resources at the bottom of this post.
Lessons learned
Career ladders should not be superimposed to teams from the outside. The creation and usage can and should be triggered and respected by the organization. But let it be some sort of team work. Let people contribute on a voluntary basis. Discuss the content and the usage. When there is some agreement about that, communicate back to the rest of the team making sure everyone understands that this was a team effort. And once again collect and discuss feedback.
Be aware that teams maybe have a heterogeneous background. So on very tightly connected teams with a shared background only some information around the career ladder and the levels therein maybe needed but on other teams you need to be more explicit and detailed in the level definition and things needed to advance. So some extra details and information might be superfluous for some team members but very well used by others.
Think about career paths. There might be more than one linear path and more than one end point if any at all. Some people like to work in tech intensive roles like developers for a certain period of time and then like to advance into more people centric roles. Some tech people don’t like the idea at all to let go of at least some of their time developing and coding and instead deal with those awkward carbon based species. Be sure to offer a way to grow also for those people. Team lead is not the natural next step after being senior engineer for some time. Maybe it will be some sort of architect role, sometimes also called principal engineer.
It’s hard if not impossible to come up with a engineering career ladder from scratch. Have a look around what other organozations do. An increasing number of companies make their career paths transparent and public. See the resources section at the bottom.
With a small team you normally don’t start with a career ladder right away. When your organization grows and your team size reaches the generally accepted management span (the number of people you can manage or care for on a direct report basis) of around 8 to 12 people this is a good point to start to think about that.
A career ladder not only consists of the levels and paths and their definition but also of the way you use and apply it, in performance reviews and promotions for example. Don’t define level transitions by the number of years of experience someone has but by their abilities. People develop with different speed and emphasis. Take that into account. Promote people to levels they already have shown to be able to do.
It’s your job as a manager to create an environment where it is OK to fail. This not only creates an emotionally save culture but also lets people try out new steps on their path to grow.Be sure to create opportunities where people can hop in and learn to grow into that new role or ability.
What about contractors?
I often see discussions about the role of contractors or freelancers in organizations. This certainly also applies to a career ladder. How you see freelancing coworkers and how you manage them depends on the role you assign to them. Traditionally contractors have one of two applications:
Firefighters: You’re project is late and you need more people working on these tasks but can not hire them permanently for any reason.
Knowledge transfer: You need some special knowledge that no one on your team has. Maybe you need it only for some time or maybe it is so rare or obscure (think of COBOL developers) that you were not able to find someone permanently.
These two are the classical or old fashioned “mercenary scenarios” of contractors. But there is another one. Some people just like to be a bit more independent or come from another background. But they will stay with your team pretty much as long as any permanent team member. The modus of payment just is different. In this case I would take those people into account with your career ladder the same way you do with permanently hired coworkers. I for example once was promoted from developer to project manager when I worked as a contractor on a team. This was the start of my “manager’s path”.
Working with agile processes is a best practice approach by now for the software development industry. It allows for small but fast steps towards a greater goal of a project or product vision. You could also apply agile thinking to research projects. Classical research is not that different from an agile process, nay? You take some small step, test a hypothesis, evaluate the result and continue with a next step.
Agility in science
But there is a fundamental difference in the concept of these processes: research allows to dismiss one or even several of the previous steps. In software development you normally don’t throw away the artifacts you built to move where you are now. For research to be agile it needs to be allowed to discard previous steps, or as Alfred North Whitehead said in “Adventures of ideas”:
A science that hesitates to forget its founders is lost.
It’s part of changing paradigms in the classical sense of Thomas S. Kuhn’s ideas in “The structure of scientific revolutions”.
There and back again
Having broadened the view on agility for research, let’s look back at software development. In agile sprints your teams makes decisions that will influence the path of the whole product. So you eventually make fast paced decisions whose effects will stay for a long time. Most software development teams are prepared to make quick technological decisions based on the problem at hand. They are normally not prepared to make estimates on the long term feasability of said decisions.
Take away
So you may accumulate technological debt even if you try to avoid. Take some pressure out of the technological decision making process by allowing for revision of architectural decisions. And last but not least establish a culture allowing to make errors. Because being under pressure to avoid errors and increase velocity makes developers susceptible for making errors. But this is a topic for another post.
Some time ago I was asked which podcasts I like and hear. There are a lot of them and I’m only listening to a few on a regular basis. This has something to do with my preferences when hearing. I don’t like long podcasts (more than 1 hour). So there are a lot podcasts of high quality that I listen to from time to time.
I tried to sort them roughly by topic and add small flags for the language of the podcast (german or english (I apologize for not being able to list an american and a british flag ;) ), so here we go.
Science and Science Communication
2Scientists Curious about the cosmos? Intrigued by evolution? Two scientists put their heads together to help answer your questions.
ABCoholics Vier Themen aus Wisschenschaft und Gesellschaft. Innerhalb von 10 Minuten bringen wir’s auf den Punkt, den Blick immer auf das Wichtigste gerichtet. Einziges Kriterium für die Themenwahl: Der richtige Anfangsbuchstabe.
Ada Lovelace Day Podcast Ada Lovelace Day is an international celebration of the achievements of women in science, technology engineering and maths which aims to increase the profile of women in STEM and create new role models for both girls and women studying or working in STEM.
Anekdotisch Evident Katrin Rönicke und Alexandra Tobor färben graue Theorie mit persönlichen Erfahrungen ein. In jeder Folge unterhalten sie sich über ein Thema, das ihnen am Herzen liegt – so finden Anekdoten und wissenschaftliche Evidenz auf unterhaltsame Art zueinander.
Base Pairs Cold Spring Harbor Laboratory’s Base Pairs podcast tells stories that convey the power of genetic information – past and present. Named among the 2018 Webby Awards’ “five best podcasts in the world” for the subjects of science and education.
Bold Signals Behind every scientific innovation and discovery are the efforts of a diverse group of hard-working, dedicated people. Beneath every conversation about the structure, function, laws, and theories of science are people using their skill, knowledge, and creativity to make incremental advances to human knowledge. Between the lines of every scientific article, snippet of science reporting, and all scientific nonfiction are people boldly working against frustration, and uncertainty. From students, teachers, and professors of science, to technicians, administrators, and research assistants, to science researchers, communicators, and educators, to people who produce, consume, or apply science outside the laboratory- Bold Signals features interviews with the people involved in this wonderful, messy, awe-inspiring thing we call science.
Brain Science with Ginger Campbell Brain Science was launched in 2006 by Dr. Ginger Campbell, an experienced emergency physician with a passion for exploring how recent discoveries in neuroscience are revealing how our brains make us who we are. This podcast is for non-scientists, scientists, and everyone in between. We interview scientists and discuss the latest books about the brain. Monthy episodes resume in June 2017, but all episodes posted since January 2013 are available for FREE in iTunes. Please visit our website for more episodes and transcripts.
Chemical Dependence A podcast about the incredible chemistry that surrounds you. Weekly episodes featuring a new chemical compound each week.
Die 3 Formeltiere Ungefähr einmal im Monat ziehen Florian (Astronom), Franzi (Bioinformatikerin) und Jojo (Informatiker) aus Jena ihre Lieblings-Onesies an und diskutieren ausschweifend-wissenschaftlich über ihre Lieblingsformeln und -strukturen.
ExploreAStory A podcast about museums, science and storytelling, hosted by Emily Graslie. ExploreAStory is supported by the Field Museum in Chicago, Illinois.
Forschergeist Moderator Tim Pritlove spricht mit Wissenschaftlern und anderen Aktiven des Wissenschaftssystems über aktuelle und zukünftige Trends und Praktiken für die Bildung, der Forschung und der Organisation und Kommunikation der Wissenschaft. Die ausführlichen Interviews wenden sich vor allem an junge und angehende Wissenschaftler, die nach Möglichkeiten suchen, ihre Forschung und Lehre den neuen Bedürfnissen der Zeit anzupassen und weiter zu entwickeln. Forschergeist ist ein Projekt des Stifterverbands für die Deutsche Wissenschaft und erscheint im Schnitt alle drei Wochen neu.
Good Night Stories for Rebel Girls A fairy tale podcast about the extraordinary women who inspire us. This show is based on Good Night Stories for Rebel Girls, the global best-selling book series written by Elena Favilli and Francesca Cavallo, inspiring millions of girls and women around the world to dream bigger, aim higher and fight harder.
Open Science Radio Das Open Science Radio ist ein unregelmäßig erscheinender Podcast von Matthias Fromm, der sich mit dem Thema Open Science in seinen vielseitigen und -schichtigen Aspekten beschäftigt – von Open Access über Citizen Science und Open Data bis hin zu Öffentlicher Wissenschaft und Open Education. Dieser Podcast soll ein grundlegendes Verständnis schaffen, vor allem aber auch über aktuelle Entwicklungen informieren.
People Behind the Science Podcast Dr. Marie McNeely, featuring top scientists speaking about their life and career in science! Featuring experts in neuroscience, physics, chemistry, biology, life sciences, natural sciences, science, science policy, science communication, open journals, and more! Inspired by other scietists, Bill Nye, StarTalk, Neil deGrasse Tyson, Brain Science, Radiolab, Science Friday, Carl Sagan, grad student, post doc, Ted, Tedx, cosmos, and more.
Publish, Perish or Podcast Take a look behind the scenes of science. Join three researchers as they discuss the issues and topics behind modern research and share funny stories from their lives as scientists.
Science Communication with Dr. Mike Hi everyone and welcome to SciComm, your number one stop for science communication. Join me, Dr. Mike, every week where I’ll be talking to a new guest about their experiences in the scientific world. This may include PhD students, science communicators, industrial scientists or those simply interested in discussing the latest scientific news.
Sternengeschichten Das Universum ist voll mit Sternen, Galaxien, Planeten und jeder Menge anderer cooler Dinge. Jedes davon hat seine Geschichten und die Sternengeschichten erzählen sie. Der Podcast zum Blog “Astrodicticum Simplex”.
The Collapsed Wavefunction The Collapsed Wavefunction is a podcast to talk about chemistry and demystify the scientific process. Hosted by Chad Jones (PhD candidate, Physical Chemistry), Sam Matthews, (MSc Organic Chemistry), and Dorea Reeser (PhD, Environmental Chemistry). New episodes every other week.
The GeekGirlWeb Show The GeekGirlWeb Show is tech meets creativity, entrepreneurship and passion. We breakdown the barriers to learning and self-development. This is life as version control. Hosted by Rebecca Garcia, self-taught developer, speaker and STEM education advocate. Her purpose is to empower people through technology.
The Life Scientific Professor Jim Al-Khalili talks to leading scientists about their life and work, finding out what inspires and motivates them and asking what their discoveries might do for mankind.
Transistor Transistor is podcast of scientific curiosities and current events, featuring guest hosts, scientists, and story-driven reporters. Presented by radio and podcast powerhouse PRX, with support from the Sloan Foundation.
Undiscovered A podcast about the left turns, missteps, and lucky breaks that make science happen.
WRINT: Wissenschaft Worin Holger Klein und Florian Freistetter ohne wissenschaftlichen Anspruch über Wissenschaft plaudern.
ZellKultur @_adora_belle_ und @moepern erklären euch die Biologie. Vom Einzeller bis zum Homo Sapiens.
Technology, Data Science, Computers and Software Development
audiodump Malik, Johnny, Axel und Flowinho reden über Macs, Hacks und anderes Techzeug.
CaSE CaSE is an interview podcast for software developers and architects about Software Engineering and related topics. We release a new episode every three weeks.
Coding History Eine Softwareentdeckungsreise zu Anfang und Gegenwart digitaler Kultur. Weltaneignung ohne Software ist mittlerweile unvorstellbar – aber wie ist sie entstanden und wie hat sie sich seither verändert? In Gesprächen und Reportagen versucht sich dieser Podcast an der Ent-Mystifizierung digitaler Artefakte.
Data Crunch Whether you like it or not, your world is shaped by data. We explore how it impacts people, society, and llamas perched high on Peruvian mountain peaks—through interviews, inquest, and inference. We talk to interesting people doing intriguing things with data, artificial intelligence, machine learning, data science, and all things revolving around them.
Data Science Imposters Podcast Explore data science, analytics, big data, machine learning as we discuss these topics. Join us on our journey.
Developer Tea Developer Tea exists to help driven developers connect to their ultimate purpose and excel at their work so that they can positively impact the people they influence. With over 7 million downloads to date, Developer Tea is a short podcast hosted by Jonathan Cutrell (@jcutrell), CTO at Whiteboard. We hope you’ll take the topics from this podcast and continue the conversation, either online or in person with your peers.
Greater Than Code A podcast about humans and technology. Brought to you by @therubyrep.
import this Ein Podcast über die Programmiersprache Python, ihre Community, ihre beigelegten Batterien, Erweiterungen, ihre Frameworks und das ganze PyUniversum.
Mastermind.fm Join James Laws from WP Ninjas and Jean Galea from WP Mayor as they discuss the trials and tribulations on building a WordPress business. Learn how to go from freelancing to building a business, managing employees, growth hacking and more.
Mein Scrum ist kaputt Scrum kann doch inzwischen eh jeder? Von wegen! Denn – ganz unter uns: genug falsch machen kann man ohne Probleme. Daher möchten wir über Stolpersteine sprechen, über Smells und unsere Erfahrungen mitteilen. Wir, das sind Sebastian Bauer und Dominik Ehrenberg.
PHPUgly The podcast your mother warned you about. Ramblings of a few overworked PHP Developers. Hosted By @shocm, @realrideout, and @johncongdon.
Python Bytes Python Bytes is a weekly podcast hosted by Michael Kennedy and Brian Okken. The show is a short discussion on the headlines and noteworthy news in the Python, developer, and data science space.
Self-hosted Web The podcast showcasing and discussing software to host on your own server or webspace, including interviews with creators and maintainers, tips and tricks and other fascinating tidbits.
Syntax – Tasty Web Development Treats Full Stack Developers Wes Bos and Scott Tolinski dive deep into web development topics, explaining how they work and talking about their own experiences. They cover from JavaScript frameworks like React, to the latest advancements in CSS to simplifying web tooling.
t3n Podcast m t3n Podcast sprechen die t3n-Chefredakteure Luca Caracciolo und Stephan Dörner in kompakten Episoden von 30 bis 45 Minuten Länge mit wechselnden Gästen über New-Work, E-Commerce, digitales Marketing, die Startup-Szene und die digitale Transformation in Wirtschaft und Gesellschaft.
Talk Python To Me Talk Python to Me is a weekly podcast hosted by Michael Kennedy. The show covers a wide array of Python topics as well as many related topics (e.g. MongoDB, AngularJS, DevOps).The format is a casual 45 minute conversation with industry experts.
The Bike Shed On The Bike Shed, hosts Derek Prior, Sean Griffin, and guests discuss their development experience and challenges with Ruby, Rails, JavaScript, and whatever else is drawing their attention, admiration, or ire this week.
TWiML&AI (This Week in Machine Learning & Artificial Intelligence) This Week in Machine Learning & AI is the most popular podcast of its kind. TWiML & AI caters to a highly-targeted audience of machine learning & AI enthusiasts. They are data scientists, developers, founders, CTOs, engineers, architects, IT & product leaders, as well as tech-savvy business leaders. These creators, builders, makers and influencers value TWiML as an authentic, trusted and insightful guide to all that’s interesting and important in the world of machine learning and AI. Technologies covered include: machine learning, artificial intelligence, deep learning, natural language processing, neural networks, analytics, deep learning and more.
Toolsday Toolsday is a 20-ish-minute podcast hosted by Una Kravets & Chris Dhanaraj. Toolsday is about the latest in tech tools, tips, and tricks on Tuesdays at 2! (Our alliteration game is so strong).
Business
Freelancer Podcast Interviews, Stories & praktische Tipps für deinen Freelancer Alltag. Yannick und Lukas sprechen mit Freelancern über ihre Anfänge, Kundenakquise, Erfolge, Niederlagen und den ganz normalen Wahnsinn des Freelancer Alltags.
FRICTION with Bob Sutton Part organizational design. Part therapy. Organizational psychologist and Stanford Professor Bob Sutton is back to tackle friction, the phenomenon that frustrates employees, fatigues teams and causes organizations to flounder and fail. Loaded with raw stories of time pressure, courage under ridiculous odds and emotional processing, FRICTION distills research insights and practical tactics to improve the way we work. Listen up as we take you into the friction and velocity of producing made-for-TV movies, scaling up design thinking, leading through crisis and more. Guests include Harvard Business School historian Nancy Koehn, Eric Ries of Lean Startup fame, and restaurateurs Craig and Annie Stoll; as well as academic leaders from Stanford University and beyond. FRICTION is a Stanford eCorner original series.
Führung auf den Punkt gebracht In Bernd Geropp‘s Podcast dreht sich alles um Führung: Unternehmensführung, Mitarbeitermotivation, Leadership und Strategie auf den Punkt gebracht. Kein Beraterdeutsch oder Konzerngeschwätz sondern Inspiration, Tipps und Impulse für Führungskräfte, Manager und Unternehmer. Der Geschäftsführercoach spricht Klartext über Unternehmensstrategie, nachhaltige Führung, Zeitmanagement, Delegieren, Vision und Ziele. Wie bekommen Sie ein engagiertes Team und motivierte Mitarbeiter? Wie bringen Sie Ihre Unternehmensvision und Ihr operatives Tagesgeschäft in Einklang?
Leben – Führen Führen. Die wohl wichtigste Tätigkeit in unserer heutigen Berufswelt. In diesem Podcast geht es um führen, Führung, um Wirksamkeit, um Ergebnisse. Und um Spaß dabei zu haben denn all das ist nur Teil von etwas größerem: Von Ihrem Leben, liebe Führungskraft! Wie das zusammen passt? Hören Sie doch einfach rein.
Pursuit Podcast The Pursuit Podcast offers advice and new perspectives on getting things done in tech through half hour conversations with tech’s great thinkers each week. Want to learn to code? Land that great new job? Learn about how to manage your new reports? We’ve got you covered. This weekly podcast and carefully curated resources aims to leave you inspired and prepared to tackle that cool new thing.
Work in Progress Behind every working human, there’s a story. Work in Progress is a new show about the meaning and identity we find in work. Each week, hear stories of personal ambition and debilitating insecurities, great successes and abject failures, the plans we make and the luck that…happens. Hosted by Dan Misener, produced by Slack. Follow along @slackstories or slack.com/podcast
History and Culture
2debate 12 minute Oxford style debating – engaging, fun and interesting short form arguments on contemporary issues…
Anerzählt Ein täglicher 5-10 minuten langer Beitrag zum Staunen und Wundern. Teil-experimentell.
Dan Snow’s HISTORY HIT History! The most exciting and important things that have ever happened on the planet! Featuring reports from the weird and wonderful places around the world where history has been made and interviews with some of the best historians writing today. Dan also covers some of the major anniversaries as they pass by and explores the deep history behind today’s headlines – giving you the context to understand what is going on today. Join the conversation on twitter: @HistoryHit
Das geheime Kabinett In geheimen Kabinetten landete früher alles, was man in Museen der Öffentlichkeit vorenthalten wollte, weil man es für zu anstößig hielt. Dieser Podcast erzählt Skurriles, Witziges und Unglaubliches, was es nicht in die regulären Geschichtsbücher geschafft hat.
Die kleine schwarze Chaospraxis Ein prozessorientierter Podcast. Ninia LaGrande und Denise M’Baye lassen es fließen, im perfekten Imperfektionismus. Ninia LaGrande ist Autorin, Slam-Poetin und Moderatorin und lebt im Internet und in Hannover. Sie ist Teil der Lesebühne „Nachtbarden“ und wurde mehrfach ausgezeichnet, u.a. mit dem Kabarett-Nachwuchspreis „Fohlen von Niedersachsen“ und als „Kreativpionierin Niedersachsens“. Ihr Buch „… Und ganz, ganz viele Doofe!“ erschien im August 2014. http://www.ninialagrande.de/ Denise M’Baye ist Schauspielerin und Sängerin. Sie hat zwei Soloalben veröffentlich und war Gastsängerin u.a. bei “Pee Wee Ellis“ und der „Jazzkantine”. Seit vielen Jahren ist sie mit dem Worldmusikprojekt „Mo’Horizons” weltweit live unterwegs. Als Schauspielerin ist sie seit 2009 im Cast in der erfolgreichen deutschen Serie “Um Himmels Willen“ und in anderen Film und Fernsehproduktionen zu sehen. Sie arbeitet auch als Sprecherin und Moderatorin. http://www.denisembaye.de
Durch die Gegend Interviews mit Musikern, Schriftstellern, Künstlern und Philosophen finden viel zu oft in sterilen Hotellobbys oder öden Büros statt. Man sitzt sich den Hintern platt und knabbert trockene Kekse. Also sagt sich der Kölner Radiojournalist Christian Möller: Rausgehen! Rumlaufen! Reden! An Orten, die mit den Interviewpartnern zu tun haben: Wohnviertel, Geburtsstadt, Lieblingsplatz. Denn die guten Gedanken kommen im Gehen.
In trockenen Büchern Sachbücher gelten als trockene, oft schwer zu bewältigende Lektüre. Zu Unrecht! Autorin Alexandra Tobor pickt die Rosinen aus den Wissensbuchregalen und fasst deren Inhalt aus ihrem persönlichen Blickwinkel in 20-minütigen Podcast-Episoden zusammen.
Kiezrekorder Wer ist der Mann, der jeden Tag an der nächsten Straßenecke sitzt? Wohnt neben mir eine berühmte Künstlerin? Und welchen Zugang hat der blinde Musiker von nebenan zu seinem Schaffen? Im “Kiezrekorder” porträtieren Nicolas Semak und Christoph Michael Menschen der Großstadt, die ihnen auffallen und die alle etwas Besonderes tun. Ganz alltäglich. Der Kiezrekorder bietet noch eine Besonderheit: Zu jeder Folge gibt es zusätzlich eine Audio-Slideshow mit Fotografien.
Systemfehler In dem Podcast “Systemfehler” geht Christian Conradi dem Defekt auf den Grund. Wieviel Platz haben Fehler, Defekte und Abweichungen in einer Gesellschaft, die in sämtlichen Bereichen nach Perfektion strebt? Projizieren wir die vermeintliche Plan- und Steuerbarkeit, die wir mit Technologie erreichen, zunehmend auch auf uns? Wie gehen wir mit Fehlern um? “Ich will die Vielfalt des Zufalls untersuchen und die Abweichung vom Normalwert erforschen. Kurz gesagt: Ich will Geschichten über den Defekt erzählen”, verspricht Christian. Unterhaltsam, lehrreich, akustisch bunt und kurzweilig.
Young in the 80s Young in the 80s ist ein Audio-Podcast über die Zeit, in der die heute 30-jährigen groß geworden sind: die 80er-Jahre. Die Brüder Christian und Peter Schmidt gehen auf Erinnerungsreise zu den Fernsehsendungen, Filmen, der Musik und Mode, dem Spielzeug und den Alltagsthemen, die das Wesen dieser Generation geprägt haben. Warum war Knight Rider die beste Fernsehserie der Welt? Warum hören Zigtausende auch heute noch „Die drei Fragezeichen“, aber niemand mehr „Arborex und der Geheimbund KIM“? Wie kann es sein, dass irgendwer jemals Modern Talking gut gefunden hat? Wer in den 80ern aufgewachsen ist, muss diesen Podcast hören – und wer nicht, der lernt durch uns ein Jahrzehnt kennen, das von den Massenmedien geprägt wurde wie kein zweites.
Zeitsprung Zeitsprung ist ein Podcast, in dem vergessene Ereignisse, überraschende Anekdoten und Zusammenhänge der Geschichte in kurzen Episoden erzählt werden. Häufig mit ein ganz bisschen Augenzwinkern – aber immer kompetent, knallhart und quellennah recherchiert.
WDR 2 Jetzt Gote! Er ist der universelle Küchenhelfer: WDR 2 Feinschmecker Helmut Gote gibt wertvolle Tipps rund ums Kochen – von praktischen Hilfsmitteln bis zu exotischen Zutaten.
WDR 5 Alles in Butter Alltagsrezepte und Luxustipps zum Genießen: Helmut Gote und Uwe Schulz nehmen kulinarische Zeitschriften unter die Lupe. – Im Studio: Moderator Uwe Schulz und Genussexperte Helmut Gote.
The last days I listened to some episodes of a german management podcast. They discussed some common management problems or mistakes and how to avoid them. This got me thinking about my own experiences and this post is a combination of ideas from the podcast and my own thoughts. And it certainly is by no means complete or authoritative.
Micromanagement
One of the most demotivating habits is not only to set a goal but also explicitly to define how to reach it. If you are at every stage of a project informed about every detail and progress of every task, if you always work on the important tasks yourself, if you think you know more than your coworkers and can do better, if you are able to jump in with any task at hand you probably are micromanaging your team. This is demotivating since you express a lack of trust. Try to delegate tasks. Have confidence in your coworkers because without they don’t have either. Sometimes the line between giving enough information to work on a task and giving too much information so the task can be done without thinking about is a fine one. Especially founders often never learned to delegate by specifying a task at hand as detailed as needed but not more. When the results don’t match their expectations they feel confirmed in their distrust.
Additionally don’t request status information each and every day. This holds true for management, but does certainly not apply to agile processes. So what is the difference between a manager requesting to be updated every day and a daily standup, you may ask. Well the standup is the spreading of information you as a reporting team member think is noteworthy for all (!) other team members. Reporting to your manager socio-dynamically is a totally different process. There is an imbalance in power right from the setting. The (im)balance of power in conversations in general is a topic worth its own post.
The undercover expert
This is a special type of micromanager. All by themselves they think that they can accomplish the technical problems better than anybody else because there is nothing they love as much as fiddling with details and technology. The result is that they work in their company not on their company. And since they are the A-Team, made of Chuck Norris and MacGyver in one person, their idea of management is to control everything. But they will think of this as support for their coworkers. Such a manager also will never give up control, even if they try. This is because stepping out of the way because they trusts someone else to do the job is not part of their worldview.
Parsimony
To pay too much is bad, but to pay poor is even worse. So don’t pay less than average. In fact if you like to get excellent work pay more than average. Money is not everything but money can be a form of appreciation. Or rather paying poor wages is a sign of lack of appreciation. If you now say that you cannot afford to pay competitive wages then you perhaps should not hire additional employees. This sounds sharp but if your revenue is so bad that you need to cut on the wages maybe your business model or way to manage is not optimal. The laws of economy say that you can not expect to buy an excess of any good by paying poor. If you pay poor for any deliverable you have to add for the risk to do so. If you take that into account you have a bit more margin to pay.
And while we’re at it: don’t work with a bonus system. Bonuses have shown to be counterproductive to create engagement with a company or job position. Most people will do anything to comply to the results defined in their agreement on objectives. This includes taking shortcuts that in the short term work to reach a goal but might harm your company if it is not the intended way to reach the goal.
Authenticity
Be authentic. Don’t try. Be it. If you commit to deliver something do so. If you give deadlines or goals, be specific. „Somewhere around March“ is not a date. “Monday, the 25 March at 10am“ is a date. If you define dates or deadlines, take a note and write a mail so everyone knows and can keep track. If you give positive feedback, do so in public, if you have to express criticism, do it in a one-on-one. Meetings with two or more managers and one employee are not feedback but a jury. Avoid this setting in any case. You remember my remark on imbalance of power from above?
One-on-Ones
While we are at one-on-ones: it’s typical german management style to have exactly one annual personnel talk. This meeting is thought to contain feedback, objectives, personal growth (if this is a topic at all) and salary. That’s a lot of stuff that should not be combined and once a year is too infrequent. There are two main reasons why managers avoid one-on-ones.
First they might think they have not enough time for every coworker to meet once a week or biweekly. This signals „you are not important to me“. And let’s just do some math. The typical management span in a tech company is somewhere up to 10 team members. 10 conversations of half an hour make 5 hours. Every two weeks which has 80 hours if your full time week has 40 hours. That’s not very much for one of your core tasks.
Or they are afraid of the talk. Being afraid to talk to colleagues may have one of two reasons. One is you might be afraid of what you will hear. The other is that you just don’t like to communicate so much at all. If one of those applies to you you might want to think about your job choice. There is a swabian proverb: „Not beaten is praised enough“. Don’t live by that. It never has been true.
Disclaimer: I never took part in a hackathon for the reasons I explain here. So all views are deduced from observing those events and their outcome.
Rant
Under which conditions would you say a software project goes bad? Let me gather some I really dislike:
We’re in a hurry i.e. we are short in time
We are actually so short in time that we can’t complete each and every task
We don’t have a good set of requirements
Outputting something counts more than doing it right (“quick and dirty is better than nothing”)
We have so much work to do that we ignore our health condition (at least for some “sprint time”)
Nearly every condition I mentioned above can be found in a hackathon. Because it is a challenge. Work fast, achieve most. And who attends a hackathon? Young people. Developers starting their career in tech.
What do they learn in a hackathon? Work fast, complete as many tasks as possible. Doing it quick and dirty is perfectly OK. If you don’t have a specification for a task, guess whatever you think will work and implement that. It’s OK to sit 3 days (and I mean DAYS including the nights) in a room and hack right away, ignoring how your body feels.
NO. Just fucking no.
I don’t want people to learn that quick and dirty is the standard way to do things! I don’t want them to learn that scarcity in manpower, time and quality is perfectly acceptable!
To be clear: in every project I worked there are phases when time is short and we needed to do something quick and dirty. But I always try to implement things the best way I can.
“We need people who can fix things quickly!”
Training people to quick and dirty as a standard might be exactly what the organizers aim at. I prefer my coworkers to learn to do things first right and then fast. And to find shortcuts where needed.
From time to time we use iterable objects, arrays, objects implementing the \Traversable interface (which iterators also do).
In the old days, real programmers didn’t check for data types, they set sort of canary flags like this:
$obj = SOME DATA;
$isarray = false;
foreach ($obj as $item) {
$isarray = true;
// do some stuff like output of $item
}
if ($isarray === false) {
// didn't get a data array, so output some default message
}
This implements some sort of foreach {…} else {…} construct that PHP doesn’t have. Sure, it works. If you don’t turn on warnings, because if you do, you will be overwhelmed by warnings about foreach trying to act on a non-array/iterable object.
There is a solution: test your data type before running into the foreach! Yes, this means if you can not be 100% sure what sort of object you get, you have to enclose each and every foreach with an if construct. Since PHP 7.1 this block can make use of the is_iterable() function, which returns true, if the given parameter is any kind of iterable object:
$obj = SOME DATA;
if (is_iterable($obj)) {
foreach ($obj as $item) {
// do some stuff like output of $item
}
} else {
// didn't get a data array, so output some default message
}
For me this looks much better. The result is the same, but without warnings and the purpose is directly intelligible. The former example needs some thinking about the wtf factor of the code.
For PHP versions below 7.1 you can use some sort of polyfill function:
if (!function_exists('is_iterable')) {
function is_iterable($obj) {
return is_array($obj) || (is_object($obj) && ($obj instanceof \Traversable));
}
}
This website uses cookies to improve your experience. We'll assume you're ok with this, but you can opt-out if you wish.AcceptRead More
Privacy & Cookies Policy
Privacy Overview
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
 The last days I listened to some episodes of a german management podcast. They discussed some common management problems or mistakes and how to avoid them. This got me thinking about my own experiences and this post is a combination of ideas from the podcast and my own thoughts. And it certainly is by no means complete or authoritative.
The last days I listened to some episodes of a german management podcast. They discussed some common management problems or mistakes and how to avoid them. This got me thinking about my own experiences and this post is a combination of ideas from the podcast and my own thoughts. And it certainly is by no means complete or authoritative. From time to time we use iterable objects, arrays, objects implementing the
From time to time we use iterable objects, arrays, objects implementing the